







La distribuzione normale
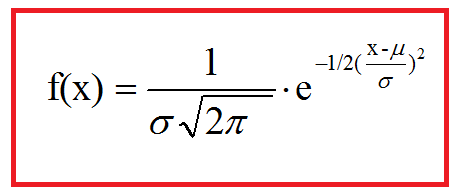
Calcolare la funzione densità della distribuzione normale:
def dnorm(x,mean=0,sd =1): from scipy.stats import norm result=norm.pdf(x,loc=mean,scale=sd) return result x= 1.2 print(dnorm(x,mean=0,sd =1))
0.19418605498321298
Nota bene!
La probabilità è la possibilità che la variabile abbia un valore specifico, mentre la densità di probabilità è la possibilità che la variabile si avvicini a un valore specifico, ovvero la probabilità su un intervallo. Quindi per ottenere la probabilità è necessario calcolare l’integrale della funzione di densità di probabilità su un dato intervallo. Come approssimazione, puoi semplicemente moltiplicare la densità di probabilità per l’intervallo che ti interessa e questo ti darà la probabilità effettiva.
Esempio
Riprendiamo l’esercizio 1 visto in Esercizi svolti sulla distribuzione normale standard:
Data la variabile aleatoria normale standard Z, si calcoli la probabilità che Z sia minore o uguale di 1,2.
Soluzione
La probabilità che una variabile aleatoria normale standard Z sia minore o uguale ad un certo valore x, ovvero P(Z ≤ x)

è un valore che, per la variabile aleatoria normale standard, viene riportato in Tabella. Tale probabilità si ricava nel modo seguente: le righe della tabella corrispondono alla cifra intera ed alla prima cifra decimale del valore x, mentre le colonne della tabella corrispondono alla seconda cifra decimale del valore x. Quindi, per calcolare la probabilità che Z sia minore a 1,2, si dovrà considerare il valore riportato in tabella relativo alla riga 1,2 ed alla colonna 0. Il valore corrispondente è 0,8849. Si avrà:
P(Z ≤ 1,2) = 0,8849
In Python:
def dnorm(x,mean=0,sd =1): from scipy.stats import norm result =stats.norm.cdf(x,loc=mean,scale=sd) return result # il nostro esercizio: x= 1.2 print(dnorm(x,mean=0,sd =1))
Esercizio 6
Data la variabile aleatoria normale standard Z, si calcoli la probabilità che Z sia maggiore di 2,98.
Soluzione
La probabilità che una variabile aleatoria normale standard Z sia maggiore di un certo valore x, è uguale al complemento ad uno della probabilità che la variabile aleatoria normale standard Z sia minore o uguale ad x, ovvero

P(Z > x) = 1 – P(Z ≤ x)
La metodologia da seguire per la risoluzione dell’esercizio è adesso analoga a quella illustrata nei casi precedenti. Per calcolare la probabilità che Z sia maggiore a 2,98, si dovrà considerare il valore riportato in Tabella. relativo alla riga 2,9 ed alla colonna 0,08.
Il valore corrispondente è 0,9986. Si avrà:
P(Z > 2,98) = 1 – P(Z ≤ 2,98) = 1 – 0,9986 = 0,0014
In Python:
def grnorm(x,mean=0,sd =1): from scipy.stats import norm result =stats.norm.sf(x,loc=mean,scale=sd) return result # il nostro esercizio: x= 2.98 print(grnorm(x,mean=0,sd =1))
Per trovare la probabilità che la variabile abbia un valore MAGGIORE O UGUALE ad un certo x useremo la funzione:
stats.norm.sf(x,loc=mean,scale=sd)
Esercizio 12:
La variabile aleatoria X ha la distribuzione normale con valor medio µ = 19 e varianza σ2= 49; determinare il valore xα tale che:


In Python:
Punto a)
def intnorm(x,mean,sd ): from scipy.stats import norm result =stats.norm.ppf(x,loc=mean,scale=sd) return result # il nostro esercizio ( punto a): x= 0.8 mean = 19 sd = 7 print(intnorm(x,mean,sd))
27.970860958812203
Esercizio 8:
Il punteggio ottenuto in un test sul quoziente di intelligenza è una variabile aleatoria X avente distribuzione normale con media µ = 100 e deviazione standard σ = 15.
Trovare la probabilità che il punteggio ottenuto da un candidato sia compreso fra 100 e 112.
⇒ 
In Python:
def betweennorm(x1,x2,mean,sd ): from scipy.stats import norm result = stats.norm(mean, sd).cdf(x1) - stats.norm(mean, sd).cdf(x2) return result # il nostro esercizio: x1= 112 x2 = 100 mean = 100 sd = 15 print(betweennorm(x1,x2,mean,sd))
0.28814460141660336
Generazione di numeri casuali con distribuzione normale
def rnorm(n,mean=0,sd=1):
from scipy.stats import norm
result=norm.rvs(size=n,loc=mean,scale=sd)
return result
n =19
print (rnorm(n,mean=0,sd=1))
[elementor-template id=”12586″]
[no_toc]
(1488)
Altri articoli nella categoria "Esercizi svolti di Statistica"
- Analisi Statistica Avanzata: Indice di Gini, Asimmetria e Proprietà dei Residui nella Regressione
- Esercizi Svolti di Statistica Descrittiva: Mediana, Varianza, Box Plot e Correlazione (Con Spiegazioni)
- La Città dei Numeri Manipolati: Gioco Interattivo per Riconoscere le Fake News Statistiche
- Media, Mediana e Moda: 8 Esercizi Svolti dalla Base all’Analisi Avanzata
- Data Literacy: 5 Esercizi per non farsi ingannare dai Grafici (Statistica Pratica)
- Data Literacy: Guida Pratica per Interpretare Grafici Statistici (con Esercizi e Soluzioni)
- Come leggere le Tavole Statistiche (Z, t, Chi-quadrato): Guida Completa ed Esempi
- Come scegliere il test statistico giusto per decisioni aziendali: 3 esempi pratici nel Retail
- Guida Pratica alla Statistica: Esercizi Svolti dalla Descrittiva al Test d’Ipotesi
- Cos’è la Multicollinearità, come si calcola il VIF e come risolvere la ridondanza dei dati nella Regressione Lineare