

Indice
Distribuzioni di frequenza
Quando si raccolgono dei dati su una popolazione o su un campione, i valori ottenuti si presentano allo statistico come un insieme di dati disordinati; i dati che non sono stati organizzati, sintetizzati o elaborati in qualche modo sono chiamati dati grezzi. A meno che il numero delle osservazioni sia piccolo, è improbabile che i dati grezzi forniscano qualche informazione finché non siano stati ordinati in qualche modo.
In questo articolo verranno descritte alcune tecniche per organizzare e sintetizzare i dati in modo da poter evidenziare le loro caratteristiche importanti e individuare le informazioni da essi fornite.
In questo contesto non è importante se tali dati costituiscono l’intera popolazione o un campione estratto da essa. Consideriamo i seguenti esempi.
Esempio 1
Rilevando con uno strumento di misurazione il numero di particelle cosmiche in 40 periodi consecutivi di un minuto si ottengono i seguenti dati

Esempio 2
I seguenti dati sono il risultato di 80 determinazioni, in una data unità di misura, dell’emissione giornaliera di un gas inquinante da un impianto industriale

Esempio 3
In uno stabilimento vengono registrati i casi di malfunzionamento di una macchina utensile controllata dal computer, e le loro cause. I dati relativi a un certo mese sono i seguenti

In ciascuno degli esempi si osserva una variabile, che è rispettivamente
1 – il numero di particelle rilevate in un intervallo di un minuto;
2 – la quantità di gas inquinante emesso in un giorno;
3 – la causa di un guasto verificato.
Della variabile in questione abbiamo un insieme di n osservazioni registrate (negli esempi n vale, rispettivamente, 40, 80, 48), che costituiscono i dati da analizzare.
Classificazione delle variabili.
Le variabili oggetto di rilevazioni statistiche si classificano in più tipi diversi, a seconda del tipo di valori che assumono

Una variabile si dice numerica se i valori che essa assume sono numeri, non numerica altrimenti;
una variabile numerica si dice discreta se l’insieme dei valori che essa a priori può assumere è finito o numerabile
(Ricordiamo che un insieme numerabile è un insieme che si può mettere in corrispondenza biunivoca con
l’insieme dei numeri interi positivi), continua se l’insieme dei valori che essa a priori può assumere è l’insieme R dei numeri reali o un intervallo I di numeri reali.
Le variabili degli esempi 1 e 2 sono numeriche, la variabile dell’esempio 3 è non numerica. La variabile dell’esempio 1 è discreta, perché il numero di particelle osservate è sempre un numero intero maggiore o uguale a 0, e l’insieme dei numeri interi è infinito ma numerabile; la variabile dell’esempio 2 è invece continua, perché la misura della quantità di gas emesso può essere un numero reale positivo qualunque (in un certo intervallo).
Molto spesso i valori assunti da una variabile continua sono risultati di misure.
Si osservi che, per decidere se una variabile è discreta o continua, occorre ragionare su quali sono i valori che a priori la variabile può assumere e non sui valori effettivamente assunti: è evidente infatti che i valori assunti in n osservazioni saranno al più n, quindi sempre in numero finito.
Per studiare i dati degli esempi precedenti dividiamo i dati stessi in classi e determiniamo il numero di individui appartenenti a ciascuna classe, detto frequenza della classe. Costruiamo poi la tabella di distribuzione di frequenza, ossia una tabella che raccoglie i dati secondo le classi e le corrispondenti frequenze.
I dati ordinati e riassunti nella tabella di distribuzione di frequenza sono detti dati raggruppati.
Esempio 4 – Variabili numeriche discrete
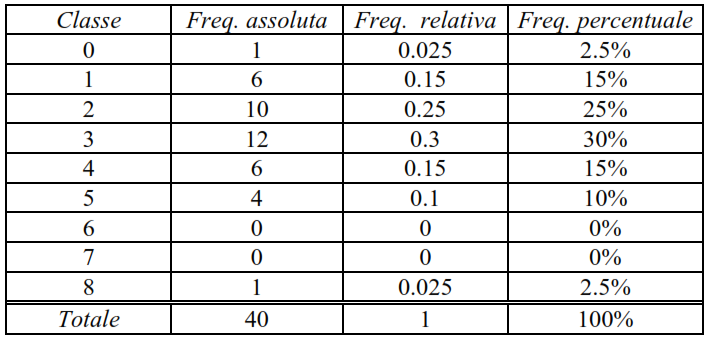
Nell’esempio 1 la variabile x osservata è una variabile numerica discreta, che può assumere solo valori interi; poiché i valori assunti sono i numeri interi 0, 1, 2, 3, 4, 5, 8, è naturale scegliere come classi i numeri k = 0, 1, 2, 3, 4, 5, 6, 7, 8 e contare per ogni classe il numero di osservazioni in cui sono state rilevate esattamente k particelle. In questo modo si costruisce la seguente tabella di distribuzione di frequenza.
Nella tabella la prima colonna indica la classe; la seconda la frequenza assoluta, detta anche semplicemente frequenza di classe, ossia il numero di osservazioni che cadono in ciascuna classe;
la terza colonna la frequenza relativa, ossia il rapporto tra frequenza assoluta e numero totale di osservazioni (in questo caso 40); la quarta è la frequenza percentuale, ossia la frequenza relativa moltiplicata per 100.
Osservazione
Si osservino le seguenti proprietà dei numeri riportati nella tabella di distribuzione di frequenza (tabella 4): la frequenza assoluta è un numero intero compreso tra 0 e il numero totale di osservazioni; la frequenza relativa è un numero reale compreso tra 0 e 1; la frequenza percentuale è un numero reale compreso tra 0 e 100.
La somma delle frequenze assolute è sempre uguale al numero totale di osservazioni; la somma delle frequenze relative è sempre uguale a 1; la somma delle frequenze percentuali è uguale a 100; i valori ottenuti come quozienti devono essere spesso arrotondati e questo fatto comporta che la somma di tutte le percentuali può non essere esattamente uguale a 100.
Esempio 5 – Variabili numeriche continue
Nell’esempio 2 la variabile osservata è continua. I valori dei dati sono compresi tra 6.2 e 31.8; il campo di variazione o range dei dati, cioè la differenza tra il più grande e il più piccolo, vale
R = 31.8 − 6.2 = 25.6
Scegliamo come classi i 7 intervalli
5.0 ≤ x ≤ 8.9
9.0 ≤ x ≤ 12.9
13.0 ≤ x ≤ 16.9
17.0 ≤ x ≤ 20.9
21.0 ≤ x ≤ 24.9
25.0 ≤ x ≤ 28.9
29.0 ≤ x ≤ 32.9
Il modo di scegliere le classi non è unico: potremmo scegliere un numero differente di classi, o classi con estremi diversi; in ogni caso le classi non devono sovrapporsi e devono contenere tutti i dati. Di solito le classi hanno tutte la stessa ampiezza, ma questa caratteristica in generale non è obbligatoria e in certi casi il tipo di dati può suggerire la scelta di classi di ampiezza diversa; inoltre, per dati continui, è necessario specificare se le classi sono chiuse a destra e/o a sinistra, ossia se i dati coincidenti con gli estremi della classe devono essere raggruppati nella classe stessa o in una delle classi adiacenti.
Troppe classi rendono la tabella poco leggibile; troppo poche classi la rendono poco significativa:
il numero delle classi è normalmente compreso fra 5 e 15; se i dati sono molto numerosi si può arrivare a usare un massimo di 20 classi.
Come scegliere il numero di classi.
Una semplice regola pratica che si rivela a volte utile consiste nello scegliere un numero di classi approssimativamente uguale alla radice quadrata del numero dei dati

Un’altra regola consiste nell’applicare la seguente formula:

dove n rappresenta il numero dei dati presi in considerazione e N il numero delle classi da usare.
Come scegliere l’ampiezza delle classi.
L’ampiezza delle classi (nel caso di classi di uguale ampiezza) può essere determinata applicando la formula:

dove R è il campo di variazione dei dati.
Le risposte ottenute applicando queste formule devono essere comunque interpretate come indicazioni di massima, da valutare caso per caso, a seconda dei dati da trattare.
Nell’esempio che stiamo esaminando si ha:
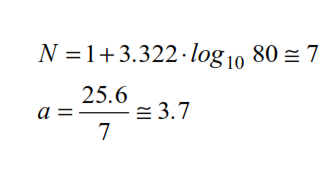
Si giustifica così la scelta di 7 classi di ampiezza 4.
Una scrittura del tipo 5.0 ≤ x ≤ 8.9 , definente una classe, è detta intervallo della classe; i numeri 5.0 e 8.9 sono detti limiti inferiore e superiore della classe.
Con la scelta delle 7 classi indicate si ottiene la tabella seguente:
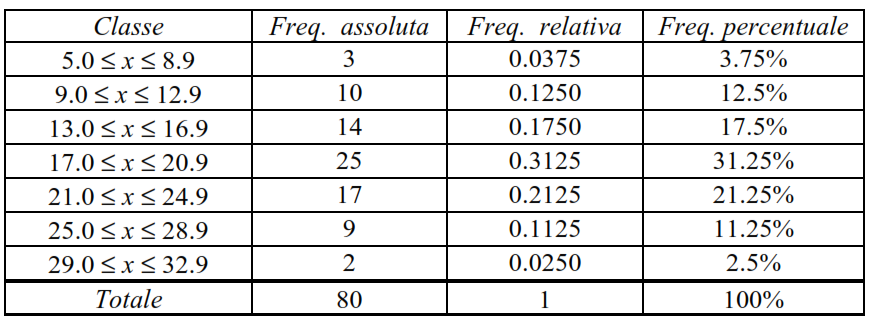
Si noti che le classi sono chiuse e che i limiti delle classi utilizzate per la tabella precedente sono assegnati con tanti decimali quanti ne possiedono i dati.
Le classi hanno uno “stacco” per evitare ambiguità. Infatti se si scegliessero ad esempio le classi
5.0 ≤ x ≤ 9.0
9.0 ≤ x ≤ 13.0
……………..
il dato 9.0 potrebbe andare nella prima classe o nella seconda, e così via.
Per evitare questa difficoltà si potrebbero scegliere le classi
4.95 ≤ x ≤ 8.95
8.95 ≤ x ≤ 12.95
12.95 ≤ x ≤ 16.95
16.95 ≤ x ≤ 20.95
20.95 ≤ x ≤ 24.95
24.95 ≤ x ≤ 28.95
28.95 ≤ x ≤ 32.95
Si può notare che anche se i limiti delle classi si sovrappongono, non ci sono ambiguità, perché questi limiti sono valori che i dati non assumono, dal momento che i dati hanno un solo decimale.
Questa scelta però non è particolarmente felice, in quanto l’uso di più decimali appesantisce la scrittura delle classi.
E ‘ più consigliabile scegliere classi aperte a sinistra, ad esempio
5 < x ≤ 9
9 < x ≤ 13
……………..
29 < x ≤ 33
oppure classi aperte a destra
5 ≤ x < 9
9 ≤ x < 13
……………..
29 ≤ x < 33
Con quest’ultima scelta delle classi, per la distribuzione di frequenza si ottiene una distribuzione di frequenza uguale a quella della tabella 5

Una volta che i dati sono stati raggruppati, ciascun valore esatto dei dati non è più utilizzato: si rappresentano tutti i dati appartenenti a una certa classe con il suo punto medio, detto valore centrale della classe.
Per ciascuna delle scelte proposte per le classi in questo esempio, le classi hanno la stessa ampiezza, uguale a 4; tale ampiezza è uguale alla differenza tra due valori centrali successivi o anche alla differenza tra due limiti inferiori (o superiori) di due classi successive.
Con i dati dell’esempio 5 e con la scelta delle classi aperte a destra (tabella 5b) si ottiene
a − valori centrali delle classi

b − ampiezza di classe
![]()
Il procedimento di raggruppamento dei dati fa perdere alcune delle informazioni che provengono dai dati: ad esempio invece di conoscere l’esatto valore di un’osservazione, si sa solo che cade in un certo intervallo. Ciò accade per la distribuzione di frequenza di ogni variabile continua. Tuttavia si trae un importante vantaggio dalla “leggibilità” che si ottiene e dalle relazioni fra i dati che si rendono evidenti.
Come analizzare le variabili non numeriche.
Le frequenze cumulative.
(988)